This is a Gartner Article written by Ted Friedman, Nick Heudecker
Refreshed 2 June 2021, Published 13 February 2020 - ID G00465401 - 12 min read
Many data and analytics leaders think of data hubs, data lakes and data warehouses as interchangeable alternatives. In reality, each of these architectural patterns has a different primary purpose. When they are combined, they can support increasingly complex, diverse and distributed workloads.
Overview
Key Challenges
-
Data and analytics leaders are often unclear about the differences between data lakes, data warehouses and data hubs. Positioning them as competing approaches creates confusion.
-
Without a clear understanding of the specific roles and capabilities of each structure type, data and analytics teams miss opportunities to provide the best support for specific business requirements.
-
Many organisations also overlook the value of using data lakes, data warehouses and data hubs together. Combinations of these structures can be used to support a more diverse set of data and analytics use cases.
Recommendations
Data and analytics leaders seeking to modernize their data management solutions and the supporting architectures should:
-
Distinguish between these structures by recognizing their differences in focus. Data warehouse and data lakes exist primarily to support analytic workloads. In contrast, data hubs are not primarily analytic structures — they enable integration, sharing and governance of data.
-
Eliminate confusion and ensure alignment of approach with business requirements by communicating the characteristics and common use cases for each of these structures.
-
Maximize your ability to support a broader range of diverse use cases by identifying the ways that these structures can be used in combination. For example, data can be delivered to analytic structures (data warehouses and data lakes) using a data hub as a point of mediation and governance.
Strategic Planning Assumption
By 2021, enterprises using a cohesive strategy incorporating data hubs, lakes and warehouses will support 30% more use cases than competitors.
Introduction
Data continues to grow more diverse and more distributed — as do the sources of data and points of data consumption. At the same time, analytical needs and operational uses of data are proliferating across the enterprise and beyond. Stakeholder needs can no longer be met by traditional architectures that are based on centrally collecting data and enable predefined uses. Data and analytics leaders and their teams need to deliver a modern data management infrastructure that supports flexibility, diversity of data needs and connectedness.
This requires a combination of different data organization and processing approaches. However, some data and analytics teams are still focused on meeting all needs using a single architectural pattern — either a traditional enterprise data warehouse, a modern data lake or a data hub.
There is significant confusion between these concepts. Many organizations will use these terms interchangeably or will use the same term to mean different things in different scenarios. For example, while Gartner client inquiries referring to data hubs increased by 20% from 2018 through 2019, more than 25% of these inquiries were actually about data lake concepts. This suggests that there is confusion about or misuse of the terminology.
There is also a lack of clarity about the roles of data warehouses and data lakes. An estimated 30% of clients posing data lake inquiries are either considering a data lake as a replacement for a data warehouse or are otherwise unclear about the relationship between data lakes and data warehouses.
All three of these architectural patterns (data warehouses, data lakes and data hubs) are key areas of investment (see Figure 1). However, there is a need for greater clarity and focus. Data and analytics leaders must understand the purpose of these three types of structures and the role they can play in a modern data management infrastructure. This will help them to appropriately map capabilities to requirements and capture the maximum range of use cases.
Figure 1. Data Warehouses, Data Lakes and Data Hubs Are All Significant Areas of Investment

Analysis
Distinguish Between Data Warehouses, Data Lakes and Data Hubs, and Recognize How They Differ in Focus
As a fundamental principle, data and analytics leaders need to recognize that each of these structures serves different goals. They can be readily segmented by considering four key aspects of data management (as outlined in Figure 2). Comparing data warehouses, data lakes and data hubs across these aspects can help data and analytics leaders to identify:
-
How these structures are similar.
-
How these structures differ.
-
The roles these structures are likely to play in a data management infrastructure.
Figure 2. Clarifying the Focus and Key Data Management Aspects of Data Lakes, Warehouses and Hubs

Data warehouses and data lakes are similar. Both provide an endpoint for collection of transactional, detailed data (and possibly other types of data) specifically to support the execution of analytic workloads. This means that various kinds of analytics can be run atop them, accessing the data they hold to support analytic processing. As a result, both data warehouses and data lakes have a common focus — supporting the analytic needs of the enterprise. While data warehouses and data lakes may also include governance controls (for example, they can provide monitoring and resolution of quality issues in inbound data), they support governance in a more reactive and “downstream” manner.
Data hubs are quite different because they generally do not store detailed data for extended periods. Also, data hubs are not repositories on which analytic workloads are generally executed. Rather, they are points of mediation and data sharing. Data hubs enable data flow in the enterprise by connecting producing systems and processes with consuming systems and processes. For example, a data hub can be used to connect business applications to a data warehouse or a data lake. They also proactively apply governance controls to the data flowing across the infrastructure.
Data warehouses and data lakes are structures supporting analytic workloads. Data hubs are different — their main focus is enabling data sharing and governance.
As a result, data and analytics teams should think of data warehouses and data lakes as similar types of structures. Their primary purpose is to support analytics (albeit of different styles). In contrast, data and analytics leaders should think of data hubs as more operational structures, focused on enabling data sharing and governance.
Communicate the Characteristics and Common Use Cases for Each of These Structures
Data and analytics teams should agree on a clear definition and understanding of each of these structure types. They must then communicate these definitions to all stakeholders. This will avoid confusion and ensure that misuse of terminology does not lead to a disconnect between expectations and reality. Gartner defines these structures as follows:
-
Data warehouse — A data warehouse is a collection of data in which two or more disparate data sources can be brought together in an integrated, time-variant information management strategy. Data warehouses generally house well-known and structured data. They support well-known, predefined and repeatable analytics needs that can be scaled across many users in the enterprise. As such, data warehouses are best suited to the requirements of moderate to highly consistent semantics. Also, they generally support a fairly fixed processing strategy (SQL-oriented access to a central physical data store). Data warehouses are suited to complex queries, high levels of concurrent access and stringent performance requirements.
-
Data lake — A data lake collects unrefined data (that is, data in its native form, with limited transformation and quality assurance) and events captured from a diverse array of source systems (see “How to Avoid Data Lake Failures”). Data lakes usually support data preparation, exploratory analysis and data science activities — potentially across a wide range of subjects and constituents. As a result, data lakes support highly variable semantics, a generic set of analytics use cases, and a range of different processing styles and approaches (including data discovery, machine learning and heavy batch computation).
-
Data hub — Unlike data warehouses and data lakes, data hubs are not focused on analytical uses of data. Rather, a data hub is an architectural pattern that enables the seamless flow and governance of data (see “Use a Data Hub Strategy to Meet Your Data and Analytics Governance and Sharing Requirements” and “Data Hubs: Understanding the Types, Characteristics and Use Cases”). Producers and consumers of data connect with each other through the data hub, with governance controls and common models applied to enable effective data sharing. Data hubs are mainly focused on driving consistent semantics. They can support a range of use cases — most often operational in nature (such as the provisioning of master data to enterprise applications and processes). They can also support a range of processing strategies (by allowing choices of data persistence techniques, integration styles and access methods).
It is important to recognize that while these definitions and characteristics represent common boundaries, there are overlaps. For example:
-
A data warehouse can support some types of exploratory analytics. This is done by providing users with the right tools — including less-structured data with varying semantics — and enabling a limited range of processing styles.
-
Some data hubs do persist detailed data (possibly for shorter timeframes) and some reporting/business intelligence (BI) workloads can be executed there.
While the optimal use for each structure may be quite different, the distinction between them can become blurred depending on design approaches and technology choices.
Maximize Your Ability to Support a Broader Range of Diverse Use Cases Through Combinations of These Structures
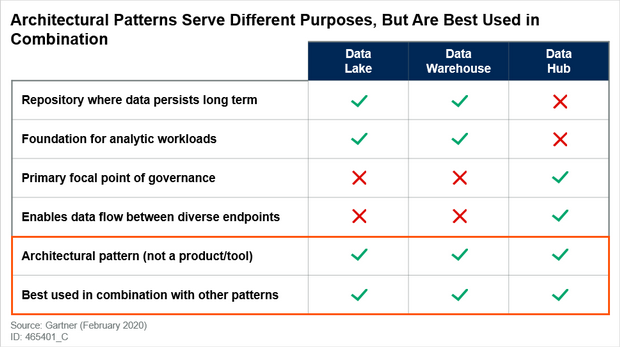
It is important to recognize the differences between data warehouses, data lakes and data hubs, and the role of each in the infrastructure. However, data and analytics teams must also understand how these structures are similar. Each of these structures exists as an architectural pattern — not a single tool or piece of technology (see Figure 3). As architectural patterns, each of these structures can be implemented in many different ways, using a variety of different technology components (see “Implementing the Data Hub: Architecture and Technology Choices” and “Building Data Lakes Successfully”).
It is equally important to recognize that these architectural patterns can bring more value to the enterprise when used in combination. Data and analytics leaders should not simply choose between either a data warehouse, a data lake or a data hub. Instead, they should consider combinations of these structures to support the full range of current and anticipated requirements. The data warehouse, data lake and data hub can be combined to work together in an effective architecture.
Figure 3. Different Purposes, But All Are Patterns Best Used in Combination
Common combinations of these structures have emerged. For example:
-
Data can be delivered to analytic structures (data warehouses and data lakes) through a data hub, which acts as a point of mediation and governance (see Figure 4). An increasing number of enterprises are applying a data hub architecture as a focal point for sharing and governance of all critical data across the enterprise. This includes provisioning of data from operational systems to analytic structures, such as data warehouses and data lakes.
Figure 4. Hub-Centric Provisioning of Data for Analytics

-
A logical data warehouse can be supported through the federation of data that resides in the data lake and the data warehouse. The different characteristics of data warehouses and data lakes mean that both patterns are increasingly required to support the diverse analytic needs of the modern enterprise. The combination of data warehouse and data lake capabilities represents a common type of logical data warehouse (see “The Practical Logical Data Warehouse: A Strategic Plan for a Modern Data Management Solution for Analytics”).
-
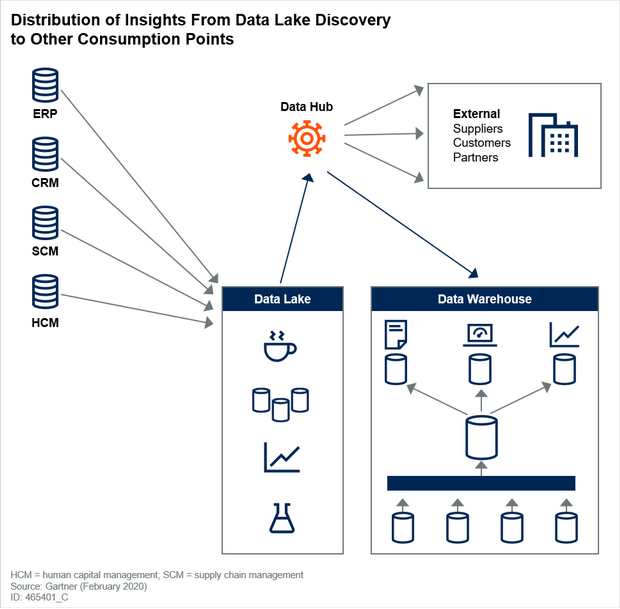
Insights derived from a data lake can be provisioned to the data warehouse (for repeatable and scalable consumption) and external consumers using a data hub (see Figure 5). Analytic workloads are growing more diverse. They can benefit (and increase the value delivered from) more and different constituents — both inside and outside the enterprise. Increasingly, organizations are looking to take emergent, exploratory insights derived in the data lake and scale them for broader, repeatable use across the enterprise through the data warehouse. Likewise, there has been an increase in demand for the ability to deliver the results of structured analyses from the data warehouse to customers, suppliers and more. Data hubs can be an effective point of governance and provisioning for these needs.
Figure 5. Distribution of Insights From Data Lake Discovery to Other Consumption Points
A key element of modern data management infrastructure is the ability to be dynamic — to evolve architectural patterns over time, enable new connections and support new use cases. Data and analytics teams should regularly review requirements to decide how to evolve. For example, they may consider:
-
Adding new endpoints to existing hub environments.
-
Creating new data hubs as new collections of endpoints with data sharing requirements emerge.
-
Shifting the relationship between data warehouses and data lakes to optimize the logical data warehouse.
Evidence
The evidence for this research note is derived from inquiries with Gartner clients, vendor briefings and primary research conducted by the authors